Automating Kubernetes Cluster Using Ansible

This article will give you a brief idea of how we can automate an entire Kubernetes Cluster Configuration using Ansible.
Kubernetes and Ansible both are the most demanding technologies in the industry. And integrating them to achieve an agile environment is something unique.
Let us have an overview of the technologies used in this blog:
KUBERNETES

- If we talk about containerization technology, it has become a new trend in the tech industry. Almost all the top MNCs have started using the containers for their benefits. But using something is not the key, managing it properly is the real challenge.
- In an environment, where we have lots of containers, managing them together becomes a headache. And this is the time when a container orchestration tool comes into play.
- Kubernetes is nothing but one of those container orchestration tools only that help us to manage our containers in the best possible ways.
Apart from managing the containers, it provides some other benefits as well that we will get to know about further in this article.
I have written one article on the use-cases of Kubernetes. To know more about Kubernetes and its use cases in the industry, you can have a look at it:
ANSIBLE

- When you are in the IT industry, you may need to configure several servers again and again. And people do not like doing the same stuff again and again.
- And from here, the role of configuration management tools like Ansible comes into play.
- Ansible is an open-source tool that is acquired by RedHat and is used for configuration management. It is built on the top of python language.
If you want to know why Ansible is so much popular in the market, I have one article where I have described the same in detail. Please go through the same:
Problem Statement
Now, we have the above problem statement for this task:
- The main aim is to automate the Kubernetes cluster using Ansible.
1. Launch ec2-instances on AWS Cloud eg. for master and slave.
2. Create roles that will configure the master node and slave node separately.
3. Launch a WordPress and MySQL database connected to it in the respective slaves.
4. Expose the WordPress pod and the client should be able to hit the wordpress IP with its respective port.
If I try to sum it up, our use case is to launch the entire Kubernetes cluster on AWS cloud, just in one click. An extra part would be launching apps like WordPress and MySQL on the top of the cluster.
Pre-requisites
Do you need any kind of knowledge before going through this article? Yes, you do. You should have a basic knowledge of :
- The AWS public cloud
- Ansible playbook and roles
- Kubernetes
So, let’s get started now.
At first, we have to create Ansible roles that will help in configuring the Kubernetes cluster on the top of the AWS cloud.
- The very first step is to create an Ansible role. Here, we will be needing two different Ansible roles, one for configuring the Kubernetes master node and the other for configuring the Kubernetes slave node.
- To create an Ansible role, we have the above command:
ansible-galaxy init [role_name]Inside every role, we generally use the above directories:
- Files: To store any static files, we use this folder. These static files then can be copied from the managed node to the target node.
- Handlers: When we have a requirement to run any task under a condition, and it should depend on one of the tasks as well, in that case, we use handlers and put the data in the ‘main.yml’ file under this directory.
- Tasks: This is the most crucial and most useful directory. We put all the required tasks in the ‘main.yml’ file under this directory only.
- Templates: We put all the dynamic files in this folder, the use case is to copy them to the target node only.
- Vars: Inside this directory, we have a ‘main.yml’ named file where we declare all those variables that will be further used anywhere in the tasks, handlers or even inside the files.
After creating the first role i.e., for Kubernetes master node configuration, here is the ‘main.yml’ file’s content inside the tasks directory:
- At first, I have installed the required packages such as ‘docker’ and ‘iproute-tc’.
- Next, I have created a yum repo for ‘kubelet’, ‘kubectl’ and ‘kubeadm’ and installed them simultaneously.
- In the next step, I have updated the kernel settings.
- Copying the configuration file of docker to the target node would be the next step.
- After that, I have started the ‘docker’ and ‘kubelet’ services.
- In the next steps, I have initialized the cluster using the ‘kubeadm init’ command and then configured the respective configuration files.
- Installing the CNI (here, Flannel) plugin was the next step.
- And finally, I have stored the join token in my controller node. I will transfer it to the slave node to connect it to the master.
In the above code, I have used a variable called ‘pod_cidr_network’. You might be wondering where this variable has been actually defined. So, this variable has been defined in the ‘main.yml’ file under the ‘vars’ directory:
# vars file for kube_masterpod_cidr_network: 10.244.0.0/16
- Here, I am using the default Pod CIDR that is being used by Flannel CNI. You can change this as well but in case, you changed the CIDR, you might have to change the value in the Flannel’s ConfigMap as well. Please take care of the same.
- Here, I have also used a ‘daemon.json’ named file. This is one of the configuration files for the Docker container, I have used it to change the default ‘cgroup’ driver of Docker.
This file is there inside the ‘files’ directory with the following content:
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}- And hence, the Ansible Role for configuring a Kubernetes Master node has been successfully created.
Let us quickly do the same for the slave node as well:
Here is the ‘main.yml’ file under the ‘tasks’ directory:
- Here also, from installing the required packages to starting the required services, all the steps are the same as that of the master node.
- The unique thing that I needed to do was to copy the join token from my controller node to the target node and run the command to join.
Here also we are using the ‘daemon.json’ file inside the ‘files’ directory with the following content:
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2"
}Note that in this role’s task, we are not using any kind of variable.
And hence, the second role has been created as well.
Now, it is time to test these roles. And here, I am going to test these roles on the top of the AWS cloud.
Here, I have launched the above three instances on the AWS cloud, one will be the master node for Kubernetes and the other two will be the slave nodes.
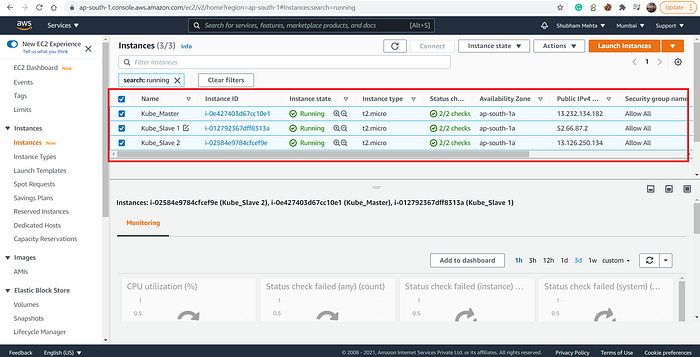
I have used the above configuration for the instances:
- AMI: Amazon Linux
- Instance Type: t2.micro (for free tier). You can also go for t2.medium or t2.large, the cluster will run smoothly then. t2.micro provides 1 GB RAM and 1 VCPU in the free tier that might cause some issue while cluster configuration.
- Security Group: Allow All (However, you can allow the specific ports used by Kubernetes components).
Rest, all the configurations are basic.
In Ansible, I am going to use the above-
Configuration File of Ansible:
[defaults]
inventory=hosts
private_key_file=/root/arthkey.pem
host_key_checking=False
remote_user = ec2-user[privilege_escalation]
become=true
become_method=sudo
become_user=root
become_ask_pass=false
Inventory of Ansible:
[master]
13.232.134.182[slave]
52.66.87.2
13.126.250.134
The following playbook has been created to use these roles and configure the Multi-Node Kubernetes Cluster:
- hosts: master
roles:
- kube_master_aws- hosts: slave
roles:
- kube_slave_aws
And that’s it. After executing the playbook, this was the result:
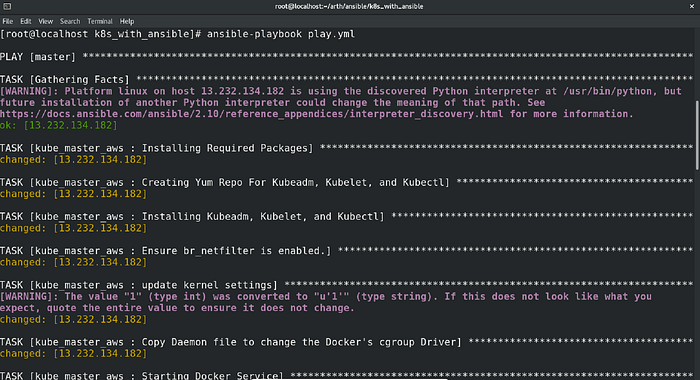
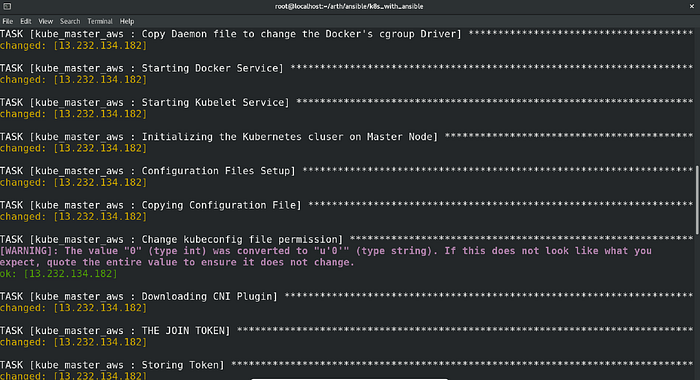
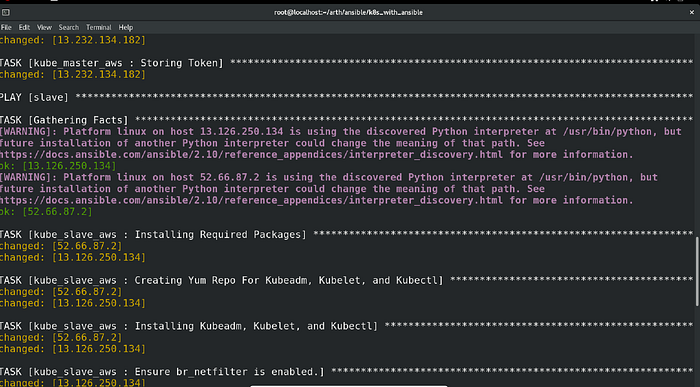
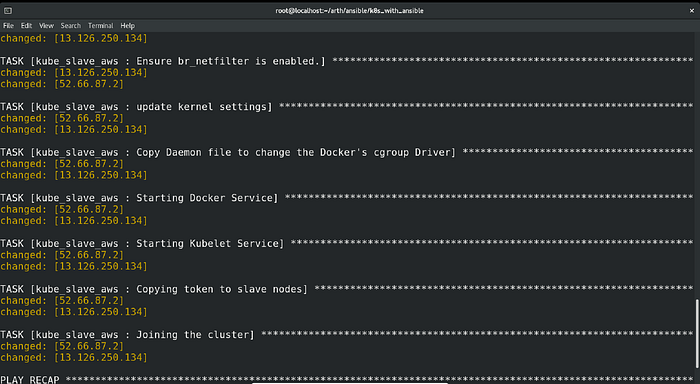
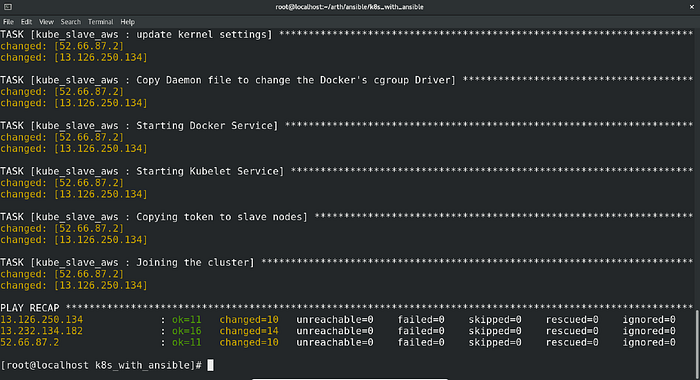
Just Amazing!! The playbook ran successfully in the very first attempt.
Let’s go inside the master node and check the same:
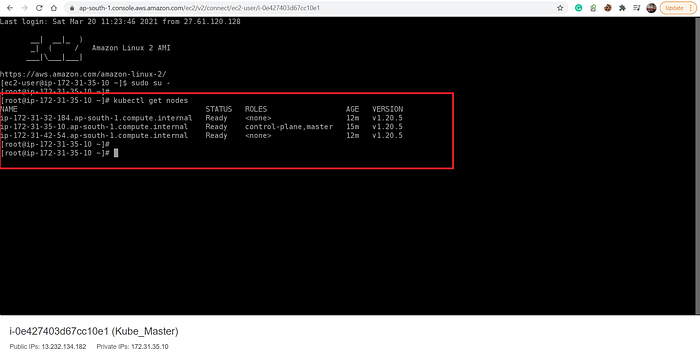
- And hence, the entire Kubernetes Multi-Node Cluster has been successfully configured on AWS cloud using Ansible in just once click.
Now, let’s do something extra. Let us try to use this Kubernetes cluster.
- I will be launching a multi-tier application set up on top of this newly created Kubernetes Cluster. I am going to use one CMS (let’s say WordPress) and one Database (let’s say MySQL) and then I will be connecting them.
- I am going to use the above deployment files for MySQL and WordPress deployment:
For MySQL:
For WordPress:
I have created the above ‘kustomization’ file to launch the entire setup in one go:
And finally, to launch the entire set up just in one click, all we need to do is to run the above command:
kubectl create -k .- If you have the ‘kustomization’ file in the same directory then use ‘dot’ (.) else you have to give the location of the file.
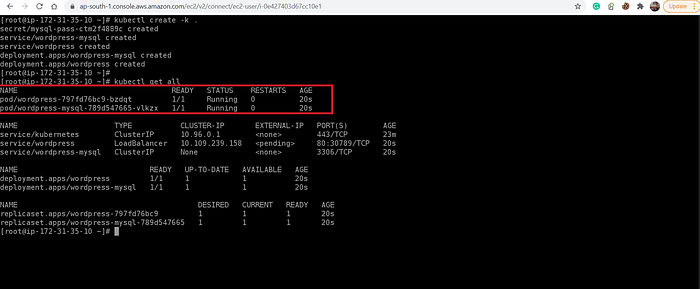
The entire workspace that I have used here, I have uploaded everything in the above GitHub repo:
Apart from the Workspace, I have also uploaded both the roles (that I created in the beginning) to the Ansible Galaxy. F
Find them in the below links:
Let’s see what do we get once we connect to the exported port of WordPress on the node’s IP:
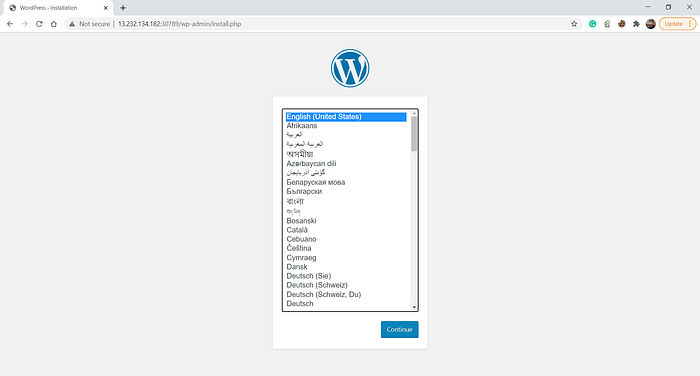
- Great! We have configured the setup successfully.
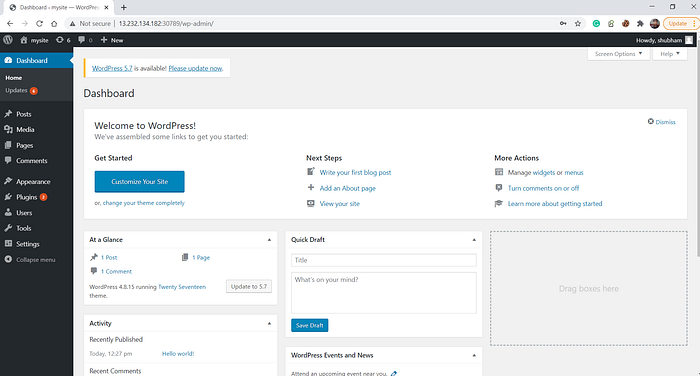
And finally, after setting up the account and logging in, we will get the above screen:
SUMMARY:
- This was just an overview of the stuff we can do after Integrating Kubernetes, Public Cloud and Ansible. Launching the entire setup within seconds using some automation script is the real thing🔥
- This specific project has an amazing future scope, we could use Ansible to configure numerous other clusters as well by writing some enormous scripts. But as of now, I will keep it simple only.😁
- I hope you got to learn something unique from the above article. I am a DevOps Enthusiast and I keep on writing similar exciting blogs on trending technologies.
- You can check out my LinkedIn profile mentioned below. Feel free to DM me in case of any queries/suggestion and follow me on Medium.